
磁盘
一个IO的访问,大致分为三个步骤,第一是磁头到指定的磁道(寻道),第二是等待需要读取的数据随盘片旋转到磁头(延迟),第三是读取数据。相比较前两个时间,读取数据的时间可以忽略不计,所以一个IO的响应时间等于寻道时间+延迟时间决定,寻道时间由于是机械的动作,所以很难得到大幅度提高,但是可以通过提高磁盘转速来提高延迟时间。所以转速越高的盘,可以承载更多的IOPS。磁盘的IOPS由磁盘的转速决定,比如15000RPM的磁盘,一般可以承受150个IOPS。
吞吐量,则由磁盘的转速和接口决定,转速决定了内部传输率,接口则决定了外部传输率,很明显前者肯定低于后者。常见的接口有ATA,SCCI,SATA,SAS,FC等等。FC接口一般在高端存储中比较常见,而SAS和SATA多在服务器或者中低端存储中常见。
存储
对于一个存储系统来说,IOPS主要决定于cache的算法,以及磁盘的数量。有时候我们往往会被厂商的数据给忽悠了,第一是cache命中率,厂 商利用了某种手段,让cache命中率非常高,IOPS几乎可以随心所欲。另外一个因素就是磁盘的数量,厂家的数据是同型号1000块磁盘的测试结果,而我们实际的系统只有100块磁盘。
购买存储时,应该避免买高端存储,而只配数量很少的磁盘,厂商非常喜欢你买一个高端的BOX,告诉你扩展性好,现在用不着可以少买点盘,以后可以扩容等等,这完全是忽悠。建议不要超前消费,如果确实对性能追求很高,可以选用容量小一些的磁盘,而磁盘的数量多一些。
磁盘的数量可以计算得出,我们的经验,一般OLTP应用的cache命中率在20%左右,剩下的IO还是要到磁盘上的,根据磁盘的转速和类型,就可 以知道一块盘能够承载的IOPS,磁盘数量就可以估算出来了,为了得到比较好的响应时间,建议每块磁盘的IOPS不要超过100。
影响吞吐量的因素稍微复杂些,由磁盘的数量和存储的架构决定,当磁盘到达一定的数量后,吞吐量主要受限于存储的架构。比如某高端存储,吞吐量最大就 是1.4GB,这是由它内部的架构所决定的。另外还要注意存储与主机的接口,比如HBA卡,有4Gb和2Gb(这里是bit,而不是Byte),一般主机和存储都配有多块HBA卡。
RAID
RAID一般比较常见的就是RAID10和RAID5,对性能要求比较高的数据库应用一般都采用RAID10,RAID5也可以用,但是别把 redo放在RAID5上,因为RAID5的对于redo这种小IO,性能非常差,很容易造成log file sync的等待。一个RAID group中的磁盘数量不宜过多,不要超过10块,原因是RAID group中磁盘数量越多,坏盘的概率就越大(概率问题)。一些高端存储对于RAID group中的磁盘数量都是固定的,这主要和存储的架构有关。使用存储的过程中,你会发现,越是高端的东西,就越是死板,而中低端存储则非常灵活,并不是说高端存储不好,而是说架构决定一切。
Stripe
Stripe的作用就是尽可能的分散IO,它在有些存储上是可以调节的,但是很多存储是不可以调节的,一般在128K-512K之间。有一个错误的 说法是,我在存储上做了stripe,数据库的一个IO,所有的磁盘都会响应这个IO。这个说法是错误的,对于Oracle来说,一个随机IO的大小是 8K,一般条带的大小要比8K大得多,所以Oracle一个随机IO永远只会落在一块磁盘上。一块磁盘在同一个时刻只能响应一个IO,也就是说磁盘没有并发IO的概念,但是从整个系统来看,不同的磁盘响应不同的IO,宏观上IO还是分散的,所以我们看到一个数据库在运行时,所有的磁盘都在忙,实际上每块磁 盘是为不同的IO服务。对于顺序IO,Oracle的默认设置是128K,最大值由OS决定,一般是1M,如果顺序IO的大小大于stripe,那么一个 IO可能会有几块盘同时响应,但是很多存储的stripe都大于128K,这时一个IO还是只有一块磁盘响应,由于读是一个顺序的过程,所以要在数据库这 个级别加上并发,才可以真正达到提高吞吐量的目的。
有人要问,stripe到底多大合适?如果我把stripe做得很小,这样不是很好吗?一个IO同时可以读很多块盘,大大提高了吞吐量。我们假设 stripe为1K,Oracle scattered read是完全串行的过程,实际上在不同的multiblock read之间,存在一定程度的并行。Oracle每次同时向OS发送若干个multiblock read IO请求,然后把返回的结果合并排序。整个scattered read应该是局部并行,宏观串行的过程。
所以stripe不能做的很小。stripe到底设多大,我的观点是大比小好,不要小于256K,数据仓库应用可以设置的更大一些。ASM对于数据 文件的stripe默认是1M,我曾经觉得1M太大,将其改为128K,结果发现1M的性能更好,Oracle也推荐用1M。这说明对于数据库应用来 说,stripe size要稍微大一点,而不是我们想的越细或者越分散越好。
存储划分
划分好的LUN输出到主机后,我们怎么用?这个就比较灵活多变,首先要看我们的用途,我们是追求IOPS还是吞吐量?我们用file system,raw devices,ASM?存储输出的LUN跨在多少块盘上?一般的存储没有虚拟化功能,则输出的LUN只跨在一个RAID group上,这时往往需要利用OS上的LVM来再次划分一次,看下面的示意图。
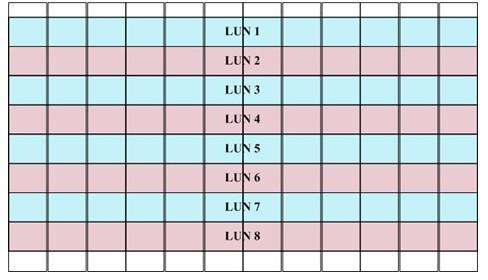
每个RAID goup有四块磁盘,建立两个LUN,输出到主机后,用蓝色的一组和红色的一组LUN分别创建两个VG,然后再创建LV(stripe),这下每个LV就 完全跨在了所有的磁盘上。实际中考虑的问题要更多,有时候不仅仅要考虑磁盘,还要考虑将负载分配在不同的控制器,前端卡后端卡和多路径的问题,相当复杂。 有些存储本身有虚拟化的功能,甚至可以输出一个LUN,比如3PAR就可以输出一个虚拟卷,这个卷已经跨在所有的磁盘上,我们直接使用就可以了(但实际工 作中这么使用的比较少见)。
Oracle有了ASM,问题就更加复杂了,我的建议是如果可以的话,存储只做RAID1,stripe交给ASM去做。如果有些存储必须要做 stripe,也没问题。存储划分是一个很有技术含量的工作,必须建立在对存储,主机和数据库深入了解的基础上,才有可能做出一个好的规划。
总结:存储是系统的最底层,因为非常重要,现在市场基本被几个大厂商所垄断,每个厂家都有一些忽悠人的名词或者商业上的炒作,所以我们要擦亮眼睛,谨防被忽悠。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
作者
相关推荐
-
冬瓜哥新作《大话存储后传》读后随感
今天要向大家隆重推荐一部有关存储的新作——冬瓜哥的《大话存储后传》,副标题是“次时代数据存储思维与技术”。
-
虚拟机监控程序使存储陷入I/O搅拌机效应
DeepStorage.net的首席研究员Howard Marks,在最近的一次虚拟化研讨会上解释了在虚拟环境中监控程序是如何影响存储I/O的。
-
Infortrend虚拟环境数据存储与备份复制方案面市
Infortrend今天宣布其ESDS 3000和EonNAS 3000系列存储系统与Veeam最新版的备份及复制软件(Backup&Replication V7)兼容。
-
华为发布OceanStor V3系列存储系统 领先开启全融合数据架构时代
华为于5月15日在北京隆重发布领先业界一代的OceanStor V3系列存储系统,借此开启面向未来的存储创新,助力客户实现精简IT,敏捷商道,引领传统企业IT的变革。