
不出所料,父母从广东搬到上海后,最不适应的就是方言:上海人听不懂广东话,他们也听不懂上海话。幸好还有普通话可以说,要不就无法跟上海人交流了。
方言导致的问题很容易理解。但是在IT领域,类似问题却困扰了很多人,尤其是当涉及到NAS共享的时候。这个类似问题就是字符编码。比如说,不同的员工使用同一个NAS共享。员工甲存的文件名是用GBK编码的,员工乙存的文件名是UTF-8编码的。双方都会觉得对方的文件名是乱码,根本无法理解。为了解决这个问题,外企员工一般使用英文,因为每种编码都能识别英文,就像上海人和广东人都懂普通话一样。但这方法并不现实,普及英文在很多单位难以做到。本文要介绍的,就是(EMC的)NAS是如何解决这个问题的。
这要从字符编码的概念开始说起:
字符(character):顾名思义,字符是文字与符号的总称。英文字母,汉字和数学符号等都是字符。
编码(encoding):计算机只能先将字符用二进制码来表示,然后再进行处理或者存储。把字符和2进制码对应起来就叫编码。比如字母A的编码就是1000001。
最早给字符编码的是美国人,他们的编码方案叫做ASCII。那时候计算机还是稀罕物,也没人想到有一天它会在全球普及。所以ASCII编码只包含了拉丁字母和符号,加起来也就100多个,用一个字节来编码就足够了(英文国家是不是文盲率很低?学好字母就差不多识字了)。
没想到计算机普及得太快了。各国人民在学会说英文之前,已经先学会使用电脑。所以很多非英文国家为自己的文字制定了符合ANSI(美国国家标准协会)标准的编码,比如中国的GB2312和日本的JIT。ANSI标准保留了所有ASCII编码,所以无论是GB2312,JIT还是其他国家的ANSI编码都支持拉丁字母。中文字符比拉丁字母多太多了,一个字节表示不完,所以GB2312用两个字节表示一个汉字。
ANSI标准解决了拉丁字母和另一种文字共存的问题,比如中文和英文可以一起出现,日文和英文也可以。但是多种非拉丁文字却无法共存,比如GB2312和JIT都不包含对方的字符,所以中文和日文就无法共存。有没有办法解决这个问题呢?还是以方言为例,我们把各地方言并在一起,看成一门语言,假如每个人都学会了这门语言,不就没有交流问题了吗?编码也一样,假如有一种编码能把世界各地的字符都编进去,各国文字就能够共存了。到了上世纪90年代,Unicode终于应运而生。它收录了超过10万个字符,包括了世界上大多数文字系统。就连不同写法的同一个字都分别编码,比如戶/户/戸等等,比孔乙己还考究。
有了Unicode,字符世界是不是就和谐了呢?事实并非如此,因为Unicode只确定了编码方式,没规定实现方法。不同的平台对Unicode有不同的实现,比较流行的有UTF-8,UTF-16等。所以Unicode虽然保证了在同一平台上多种非拉丁文字能共存,但跨平台的时候就不一定了。比如说,用UTF-16编码的客户端在NAS上存了一个中文命名的文件,用UTF-8或者GBK编码的客户端看起来还是乱码。
说完了这些背景,我们终于可以回到最初的话题:在(EMC的)NAS上是如何解决这个问题的?
答案就在下图。NAS上只存UTF-8编码。当UTF-8客户端往NAS读写文件的时候,NAS不作任何转换。当其他编码的客户端往NAS读写文件的时候,NAS就将其转换为UTF-8。有了这个转换机制,所有的客户端都感受不到编码差异。想要了解这功能如何配置,请参考EMC公开的NAS配置手册。
当然,再好的设计也不是完美的。有哪位读者能看出这个转换机制有什么潜在问题吗?请留言。
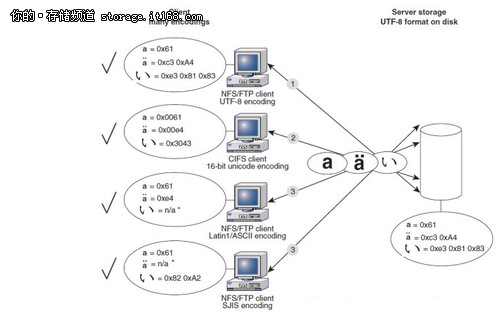
注:该图片来自EMC公开的Celerra的技术文档
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国