
灾难恢复(DR)是整个存储行业被广泛讨论的一个话题,而本文将探讨这个市场的一个具体部分:大型归档系统的灾难恢复计划。
首先来看看归档系统的定义,它特指保存信息的存储库,但其中大多数信息被访问的频率都很小。
但归档系统的定义最近也发生了变化。三四年前,归档系统一直都保存在磁带上,且只具有少量的磁盘缓存(通常少于总容量的5%)。磁带或磁盘上管理数据的软件被称为分层存储管理(HSM),35年前 HSM技术问世,被用于大型机。
现如今,一般都使用基于磁盘的大型归档系统通过网络来进行数据备份。例如,工作PC和家用PC是通过互联网进行备份,而基于云的大型归档系统也是相当普遍。
笔者对大型归档系统的定义相当简单:任何有超过2000 块SATA硬盘的系统,按照目前容量水平,大约为4 PB,明年随着硬盘容量的增加,其容量将达到8PB。在给定预期故障率的前提下,笔者使用了2000块硬盘作为归档系统大小。即使配置为RAID 6(需要2400块硬盘),在给定恢复时间内为单个应用管理这些硬盘也是很有挑战的。
三种灾难类型
需要考虑三种类型的灾难:单个文件或一组文件的丢失,元数据的损坏以及所谓的设备损坏。
单个文件或一组文件的丢失与设备损坏是两个完全不同的问题。相比彻底的灾难(地震、暴风、雷击、能源激增、洒水器等),单个文件或一组文件的丢失显得更加普遍,也更易发生。通常人们在开发系统时,都会保留至少两个数据备份。对于大型归档系统,发生灾难时考虑到重新复制数据的时间以及存储系统的数据完整性,两个备份可能是不够的。
元数据损坏问题发生的可能性不大,但确实也会发生,而且发生次数比人们预计的要多。元数据损坏可能是文件系统元数据的损坏,或在进行重复数据删除时,如果保护不力,数据块的损坏也将成为灾难。
当然,成本也在数据保护中起到了极大的作用。许多厂商都在谈论四个九、五个九、甚至八个九的可用性和可靠性。但是,当拥有PB级数据的时候,就需要重新思考这个问题。
下面的图表显示了基于几个九的可靠性下预计的数据丢失:
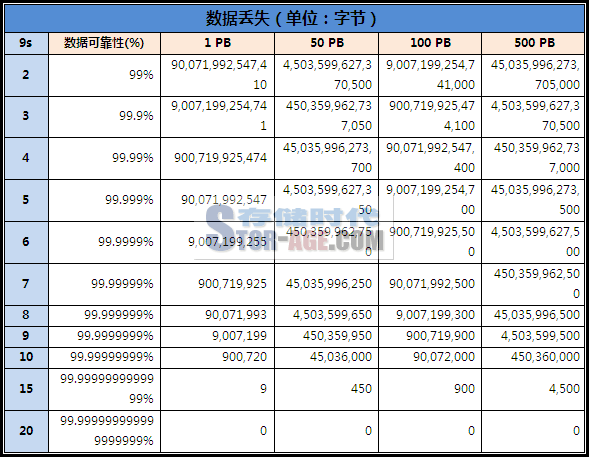
图表显示,在十个九的数据可靠性下,一千万亿字节的数据预计会丢失900720字节。因此,对于大型归档系统来说,几个九的数据可靠性也应该纳入考虑范围。一些数据保护环境是不允许发生数据丢失的,在一个企业从模拟转移到数字时,一些管理人员并不了解,数字媒体上的数据不是百分之百可靠的,拥有多个数字媒体的备份比把书放到书架要花费更多的成本,鉴于此,数据应该迁移到新媒体上,当然,不多做些数据备份,依然不能保证百分之百的可靠性。
推荐基于磁盘和磁带的归档系统
笔者建议大型归档系统使用以下数据保护策略和程序。除特别说明,这些建议均适用于基于磁盘归档系统和磁带归档系统。
数据应该实现异地同步复制、验证,且异地应选取在灾难发生区域以外的地方。例如,如果你身处一个经常发生龙卷风的地方,那么复制的地方就应选取在距本地100英里(500英里更好)以南或以北的区域,因为龙卷风一般是向东或向西行。
利用额外的ECC或可用校验来验证数据。大多数HSM系统在磁带上都具有每个文件的可用校验,但磁盘上不具备。针对磁带和硬盘的T10 DIF/PI技术在今年将会投入使用,许多厂商也在研发端到端的数据完整性技术。校验每个文件也开始成为文件系统社区关注的一部分,但校验并不能改正数据,它只能报错。如果想知道文件中错误的具体位置,就需要在文件中加入ECC,以查看、改正错误。
对于基于磁盘的归档系统,所有的RAID设备应该启用“读取奇偶校验检查”。一些RAID阵列支持这一功能,但其他的不支持。而且部分支持此功能的RAID阵列会导致性能下降。如果存储系统的故障问题导致校验失败,“读取奇偶校验检查”功能将在每个文件校验的基础上提供另一个水平的完整性。它可确保在整个文件全部丢失之前发现RAID控制器中块文件的错误。
对于基于磁带的归档系统,需要指出的是,数据不是直接移动到磁带上,而是先到磁盘,然后再通过HSM到达磁带。RAID设备应该启用奇偶校验检查。
确保对硬盘的各个方面进行软件和硬盘的误码监视。软件误码最终将转变为硬盘误码,更有可能导致文件丢失。软件误码应该在它们转变为硬件误码之前得到迅速的解决。这对于磁盘来说是一个应该注意的问题,因为其中没有自我监控、分析和检查的技术(SMART)。
如有可能的话,定期维护和备份文件系统的元数据,以及磁带中数据的HSM元数据。因为在发生故障的时候,元数据可以在没有恢复所有数据的情况下得到修复。如果文件系统中元数据和数据是分离的,这项工作将更加容易实现。
定期验证每个文件的校验。对于大型档案,考虑到CPU、内存和I/O带宽的需求,这将成为一个重大的架构问题。
基于硬盘和基于磁带归档系统的灾难恢复计划是相似的。一些技术可能不同,但关键在于定期的检查和为将会出现的灾难作准备。太多的企业不适当投资大型归档系统,同时还不希望发生数据丢失。如果拥有一个50PB的归档系统和一个复制站点,而且因为灾难而丢失了整个归档,当重新复制站点时,肯定也会丢失数据。没有任何办法可以避免媒体的硬件误码。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
翻译
相关推荐
-
数据中心灾难恢复规划模板与指南
阅读本篇有关数据中心灾难恢复规划指南,然后免费下载我们提供的模板,评估数据中心设施及其基础架构在灾难期间的表现。
-
揭开灾备真相——行业现状及趋势
笔者在上一篇文章《揭开灾备真相——那些年我们见过的灾备术语》里介绍了灾备领域常见的一些专业术语,本文将站在行业角度,介绍灾备市场的现状及未来趋势。
-
揭开灾备真相——那些年我们见过的灾备术语
作为数据保护的最后一道屏障,灾备系统的重要性不言而喻。IT圈好像一夜之间都在说灾备,那么到底什么是灾备?为什么灾备如此重要?未来发展趋势如何?本系列文章带你认清灾备真相。
-
存储经理人2017年11月刊:如何选择正确的DRaaS供应商
《存储经理人》2017年11月刊重点介绍如何选择正确的DRaaS提供商:DRaaS供应商应当具备四项关键技能,以能够全方位应对所有潜在灾害。本期杂志还介绍了下一代线性磁带开放标准LTO-8,云中数据存储的注意事项以及驱动企业采用云存储的主要因素,同时阐述了冷存储需求不断高涨以及二级存储的现代化转型等现状,提醒大家在文件同步和共享时应确保数据安全,以及如何为未来的闪存做好准备。