
首先,我所定义的归档系统指什么?大型归档系统又指什么?归档系统指由所保存的信息组成的一个存储库,但里面的信息大部分不经常被访问。
归档系统的定义最近出现了变化。就在仅仅三四年前,归档系统总是放在磁带上,磁盘缓存容量很小(通常不到总存储容量的5%)。管理磁带及/或磁盘上数据的软件名为分层存储管理(HSM)软件,是35年多以前为大型机开发的。
而如今,我们使用基于磁盘的大型归档系统,通过网络来备份数据。比如说,本人的办公电脑和家用电脑都通过互联网来备份,基于云的大型归档系统现在很常见。当然,这方面存在可靠性问题,但那是另一个话题了。
我给大型归档系统所下的定义很简单:凡是SATA磁盘驱动器数量在2000个以上的,都是大型归档系统。如今,这个容量相当于约4PB(1PB=1015字节);明年等驱动器容量增加后,可能会达到8PB。考虑到2000个驱动器的预计故障率,我现在使用2000个驱动器作为归档系统。即便在需要2400个驱动器的RAID-6配置环境中,考虑到为单单一个应用系统管理那么多驱动器所需要的重构时间,也会面临重大挑战。
三种灾难
有三种灾难需要考虑:单个文件或单组文件的故障、元数据受损,以及我经常所说的“喷洒器错误”(sprinkler error)。
单个文件或单组文件的故障这个问题与计算机房的喷洒器坏掉,因而破坏所有设备全然不同。与全面性的灾难(地震、飓风、雷击、电源浪涌和喷洒器坏掉等)相比,一个文件或一组文件出现故障的可能性要大得多,而且常见得多;但是我在设计系统架构时,常常确保数据总是至少有两个副本。而在大型归档系统中,考虑到万一发生灾难,需要从存储系统重新复制数据,并确保数据完整性,两个副本可能是不够的。
发生元数据受损问题也不太可能,但确实会发生,而且发生的频率比许多人所认为的还要高。元数据受损可能表现为文件系统元数据受损;或者,如果使用了重复数据删除技术,表现为其中一个数据块受损;要是不给予充分的保护,可能会变成一场灾难。
当然,某个站点会对数据采取多大的保护力度,成本是决定性因素。许多厂商都在谈论四个9(99.99%)、五个9(99.999%),甚至八个9(99.999999%)的可用性和可靠性。不过,如果你有数PB的数据,那么这个概念就需要重新考虑了。
下面这张表表明了基于可靠性方面9的数目而预计的数据丢失情况。
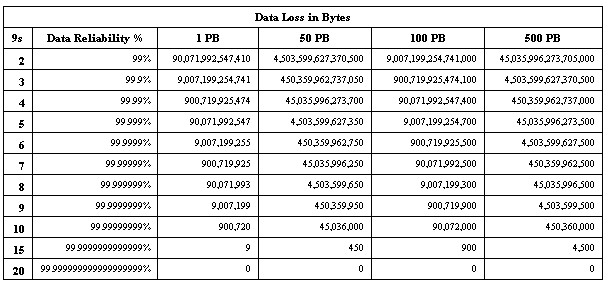
所以,如果是十个9的数据可靠性,又只有1PB数据,那么预计会丢失900,720个字节。因此,面对大型归档环境,必须重新考虑着眼于9的数目的数据可靠性。在一些数据保存环境下,不管什么原因丢失数据都是根本无法接受的。我在这种类型的环境中经常发现,当企业从模拟系统进入到数字系统后,一些管理人员不了解数据在数字介质上并非100%可靠;保有数字介质的多个副本其成本高于在书架上保有图书,那是由于数据必须迁移到新介质上;要是数据没有好多个副本,仍然不是100%可靠。
为基于磁盘和磁带的归档系统支招
我建议针对大型归档系统,应采取下列数据保护策略和程序。除非另有说明,否则这些建议同时适用于基于磁盘的归档系统和基于磁带的归档系统。
数据应同步复制到潜在灾难区域之外的另一个场地,而且数据要经过验证。比如说,假设你所在地出现了龙卷风,就应该复制到离所在地北边或南边至少100英里之外的地方——复制到至少500英里之外的地方,那就更安全,因为大多数龙卷风是沿往东或往西方向行进的。
确保有额外的纠错码(ECC)或校验和可用,以便验证数据。大多数HSM系统在磁带上提供了按文件检验和(per-file checksums),但是大多数在磁盘上没有这种校验和。面向磁带和磁盘的T10 DIF/PI等技术会在今年面市,许多厂商正在研制端到端的数据完整性验证技术。按文件检验和正开始成为文件系统领域的一个常见讨论话题,但是检验和纠正不了数据;它只能告诉你某个文件坏了。如果你想知道文件中哪个地方坏了,就需要文件中有纠错码(ECC)来检测故障,最好能纠正故障。
就基于磁盘的归档系统而言,所有RAID设备都应该启用“读操作奇偶性检验”功能。一些RAID控制器支持这项功能,而另一些RAID控制器不支持。有些RAID阵列支持这项功能,但是会引起性能大幅下降。要是存储系统里面的某个故障问题引起检验和失效,这项功能还提供了比单单拥有按文件检验和更高一级的完整性。读操作奇偶性检验可以确保:及早发现RAID控制器上的数据块故障,以免整个文件出现故障。
就基于磁带的归档系统而言,有必要指出的是,数据并不是直接转移到磁带上,而是先转移到磁盘上,然后通过HSM转移到磁带上。RAID设备同样应该启用读操作奇偶性检验功能。
确保在硬件的所有方面针对软错误和硬错误都进行了错误监测。软错误最终会变成硬错误,还有可能会变成数据故障。应该趁软错误还没有变成硬错误,迅速解决掉。这对磁带来说是个重大问题,因为自我监测、分析和报告技术(SMART)方面缺乏标准。
如果可能的话,定期保护和备份元数据,这包括文件系统的元数据和磁盘上数据的HSM元数据;因为万一出现故障,企业不必恢复所有数据,就可以恢复元数据。如果元数据和数据在文件系统中分开存放,那么这一步效果要好得多,也要容易得多。
定期验证按文件校验和。对于大型归档系统来说,考虑到所需要的处理器、内存和I/O带宽,这成了一个重大的架构问题。
为基于磁盘的归档系统和基于磁带的归档系统作灾难恢复规划大同小异。有一些技术不同,但关键还是在于定期验证,防备可能出现的灾难。而太多的企业在大型归档系统方面没有投入足够的资金,还没有预计到数据会丢失。如果你有一个50PB大小的归档系统,又只有一个复制站点,假设你因某个灾难而丢失了归档系统,那么当你重新复制站点内容时,几乎肯定会丢失数据。介质方面的硬错误率是没法回避的。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
翻译
相关推荐
-
数据中心灾难恢复规划模板与指南
阅读本篇有关数据中心灾难恢复规划指南,然后免费下载我们提供的模板,评估数据中心设施及其基础架构在灾难期间的表现。
-
揭开灾备真相——行业现状及趋势
笔者在上一篇文章《揭开灾备真相——那些年我们见过的灾备术语》里介绍了灾备领域常见的一些专业术语,本文将站在行业角度,介绍灾备市场的现状及未来趋势。
-
揭开灾备真相——那些年我们见过的灾备术语
作为数据保护的最后一道屏障,灾备系统的重要性不言而喻。IT圈好像一夜之间都在说灾备,那么到底什么是灾备?为什么灾备如此重要?未来发展趋势如何?本系列文章带你认清灾备真相。
-
存储经理人2017年11月刊:如何选择正确的DRaaS供应商
《存储经理人》2017年11月刊重点介绍如何选择正确的DRaaS提供商:DRaaS供应商应当具备四项关键技能,以能够全方位应对所有潜在灾害。本期杂志还介绍了下一代线性磁带开放标准LTO-8,云中数据存储的注意事项以及驱动企业采用云存储的主要因素,同时阐述了冷存储需求不断高涨以及二级存储的现代化转型等现状,提醒大家在文件同步和共享时应确保数据安全,以及如何为未来的闪存做好准备。