
最近我们听到了很多关于云的新闻,现在你需要考虑,你是否会采用云模式作为你存储网络架构的一部分?
云是数据存储架构规划中的一部分,正如可能会用到云的应用一样,例如Hadoop。数据复制的标准云方法就是使用低成本硬件。原理就是,你通过在发生故障的情况下复制数据来获得数据可靠性。由于我大部分的工作都是在大型存储环境下进行的,而且根据我对驱动器故障率的了解,我对使用这种方法来管理数PB要求高可靠性的数据抱有巨大的疑虑。
因此,我想做的就是,带你一步步地分析用于大多数云中的低成本硬件。我不会谈到刀片的故障率,只有存储。作为分析的一部分,我查看了所有主流磁盘制造商的网站,采用了所有厂商之间的最佳值,因此很多分析都是最理想的情况,可能你会有不同测量结果。让我们一步步地来看。
每迁移1PB数据的硬错误
硬错误率(或称为比特误码率,BER)对可靠性有很大的影响。我所查看的所有磁盘厂商都规定了1个扇区每读取10EXX比特所发生的不可恢复读取错误的误码率。

我发现,在云架构或者Hadoop中,由于考虑到企业级SAS和SATA驱动器之间巨大的成本差距,没有人会采用企业级SAS驱动器,大多数都使用了最廉价的硬件。
读取一个2TB驱动器的时间
下文中你将看到为什么这很重要的原因。现在,先看一看读取驱动器上的数据需要的时间:

占满一个通道的驱动器数量
了解占满不同速度SONET通道所需的驱动器数量是很重要的。我在去掉TCP/IP和其他封包及重试延迟对通道的影响之后估计通道的性能,在以这样的速度双向运行于全双工时通道的速率约为90%。
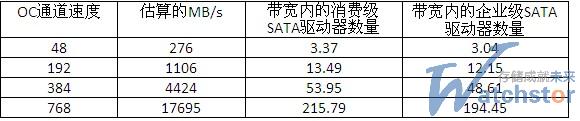
显然,占满有故障的磁盘驱动器的网络带宽并不需要大量的驱动器。
每年的磁盘驱动器故障
磁盘驱动器故障公式分为两个部分。第一个部分是基于硬错误率。如果你迁移111TB的数据,你可以假设一个磁盘无法读取写入到消费级SATA驱动器中的数据。企业级SATA驱动器的数量是1.1TB。另一个部分是年故障率(AFR)。这是每年故障驱动器占驱动器总量的比例,是驱动器厂商自己提供的一个估算值。应该注意的是,很少有驱动器厂商会提供消费级SATA驱动器的AFR数据。下表显示的是使用2TB SATA用于不同存储的驱动器数量,以及每年故障驱动器的估算量。

另一方面是基于BER的故障,因为这是基于数据迁移的,所以我再次选择了一个保守的数量,并推测驱动器占全年总带宽的5%。

为了确定总故障数量,你需要向AFR数量中增加BER(5%):

如果你使用5%这个值并除以365,那么你将得出每天的故障数量:

将总带宽利用率小幅提高到7.5%的话,将得到每天每个存储卷的故障数:

迁移数据总量的故障
下面得出的结论:当使用率为5%、存储容量为10PB的时候,每天平均你会有15个消费级SATA驱动器发生故障。在最好情况下,你大约需要24390秒通过网络进行读取或者写入每个驱动器。你最多可以获得3.37个驱动器的全部带宽,24小时获得总共276 MB/s的带宽。因此,简单计算一下,276 MB/sec×3600×24得出每天的总MB/s。对于每个驱动器,你需要82 MB/s×24390×15个驱动器故障。以下是不同情况的计算结果:
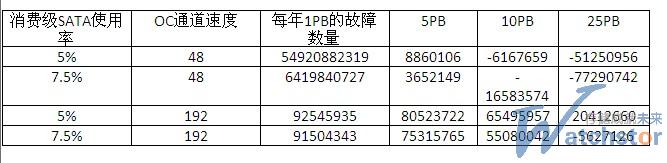
任何负数意味着驱动器复制的要求超过了通道带宽。例如,在10PB、OC-48和5%驱动器使用率的情况下,带宽相当于6167659 MB(这超过了通道带宽)或者24小时内71 MB/s。显然,随着时间的推移,这个问题越来越明显,因为你复制数据的速度还赶不上丢失的速度。
从统计概率上说,如果你有10PB的话,最终你将丢掉数据,而且不会用太长时间。唯一的架构选择就是保留数据的第三个副本,而这么做的成本很高。对于一个OC-48通道、使用率为5%的存储系统来说,拐点发生在5 PB~10 PB之间,在5 PB、使用率为7.5%的情况下,你只有42 MB/s的多余带宽(3652149,3600×24)。这时候就需要更高速的网络(付出更多成本)或者更可靠的存储(成本也不低)。
我相信云公司每天都在权衡着这些成本因素,找出什么是优化成本的最佳方法。有没有可能其中一些人并不了解基本的硬件问题?我当然希望不会是这种情况。显然,云存储适用于5PB、OC-48通达和消费级SATA存储。现在,有多少云是超过这个存储容量的?我不之道,但肯定是存在的,对于大型存储用户来说,多达10~20 PB的归档是很常见的。
云架构要比本地存储架构复杂得多。云存储可以设计成一个RAID后端,消除了很多问题,但是我所了解的大多数云由于成本因素而没有使用RAID。总的来说,云架构和云设计并不简单,对于大型数据卷来说,我看不出云比本地存储便宜多少。
驱动器可靠性和带宽将限制云的采用,而且这是一个可能永远也得不到解决的问题。带宽将越来越便宜,但是驱动器可靠性并没有多大改善,数据的增长速度仍将超过带宽。也许基于网络的重复数据删除功能会起到一些帮助作用——如果数据可以被重复数据删除的话。但是就目前来看,对于非常大型的数据存储来说,还没有一个比老式数据中心更好的选择。
我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
相关推荐
-
云中数据存储需谨慎
基于云计算的数据存储、云计算以及各种aaS形式的服务开始刷存在感,为本地基础架构蒙上了一层阴影。云服务既经济又容易使用——如果你知道诀窍的话。需慎重处理云计算问题,你可能会遇到熟悉的本地存储问题。
-
IT存储管理员:多一些业务 少一些比特
存储专家的日子可能即将结束,然而,尽管某些存储技能已经过时,但存储管理员对于企业利益的重要性也同样重要。
-
利用多云存储降低云锁定风险
多云存储的战略允许数据在不同公共云之间移动,从而避免被单个云提供商锁定,同时降低成本并提高工作负载运行效率。
-
在灾难发生之前 控制数据存储的增长!
数据已经有了自己的生命,并且一直在增长。是时候采取控制措施了。有大量的数据管理应用程序以及系统可以帮助限制和管理在企业周围浮动的数据量。例如复制数据管理(CDM)产品能很好地防止数据的激增,从而减少不必要的、不受管理的数据存储增长。