
存储极客
这是一群存储偏执狂
与你分享存储里的那点事儿

众所周知,传统存储系统对固态介质的利用方式共有多种,冬瓜哥本文就针对每一种方式做个分析和总结。虽然说论文都有个摘要,但是冬瓜哥想直奔主题,就不啰嗦了。
【方式1】连锅端/AFA
第一种是一刀切连锅端,直接把机械盘替换为固态盘,这种方式获得的性能提升最高,但无疑付出的成本也是最高的,这就是所谓All Flash Array(AFA),全闪存阵列。然而,如果不加任何改动仅仅做简单替换的话,会发现AFA根本无法发挥出固态盘的性能,比如,一个24盘位的中端存储系统控制器,如果全部换成24块SAS SSD的话,其最大随机读IOPS大概只能到200K到300K之间,如果按照每块盘随机读IOPS到50k的话,那么24块的总和应该是1200K,也就是120万,当然,还需要抛去做Raid等其他底层模块的处理所耗费的时间开销,但是,二十到三十万IOPS相对于120万的话,这效率也太低了。
全固态阵列,是一种虚拟化设备,所谓虚拟化设备,是指从这个设备的前端只能看到虚拟出来的资源而看不到该设备后端所连接的任何物理设备(带内虚拟化);或者在数据路径上可以看到后端的物理设备且可以读写,但是在控制路径上需要在对物理设备进行读写之前咨询一下元数据服务器(带外虚拟化)。带外虚拟化性能高,但是架构复杂不透明,需要在前端主机上安装特殊的客户端。带内虚拟化方式则可以对前端主机保持完全透明。目前的全固态阵列,为了保证充分的通用性,所以普遍使用带内虚拟化方式,也就是说,对于基于x86平台的AFA,其软硬件架构本质上与传统存储别无二致,差别就在于IO路径的优化力度上。传统阵列的IO处理路径无法发挥出固态介质的性能根本原因就在于参与IO处理的模块太多太冗长,因此,全固态阵列基本会在以下几个角度上做优化从而释放其所连接的固态盘/闪存卡的性能。

1. 简化功能
比如快照重删Thin远程复制、Raid2.0之流、自动分层/缓存(本来也就一个层)等。所有这些模块的存在,都会影响性能。虽然可以使用流水线化的IO处理方式来提升吞吐量,但是流水线对IO的时延是毫无帮助的,而且流水线级数越多,每个IO的处理时延就越高。吞吐量虽然是一个很重要的指标,只要底层并发度足够大(更详细的分析可参考冬瓜哥另一篇文章《关于IO时延你被骗了多久》),再加上流水线化,就可以达到很高的数字;但是时延的指标,对于一些场景来讲同样很重要,比如OLTP场景,时延只能靠缩减流水线级数(处理模块的数量)或者提升每个模块的处理速度这两种手段来实现,没有任何其他途径。然而,也并非要把所有数据管理功能全都抛掉,如果这样的话,那么所有基于x86平台的AFA最后就只能拼价格,因为没有任何特色。所以,保留哪些功能,保留下来的功能模块又怎样针对固态介质做优化,就是AFA厂商需要攻克的难关了。
2. 用原有的协议栈,加入多队列等优化
对于IO处理的主战场来讲,协议栈无疑是一道无法越绕开的城墙,拿Linux来讲,协议栈从通用块层一直延伸到底层IO通道控制器的驱动程序(Low Layer Device Driver,LLDD),IO路径上的这一大段,都可以统称为协议栈。开发者可以完全利用现有Linux内核的这些成熟的协议栈来设计AFA,但是其性能很差,比如通用块层在较老的内核版本中,其只有一个bio(Block IO)请求队列,在机械盘时代,机械盘就像老爷车一样,这个队列基本都是堵得,也就是Queue Full状态,渎指针永远追不上写指针。
而在固态存储时代,这个队列又频繁地欠载(Underrun),渎指针追上了写指针,因为底层的处理速度太快了,以至于队列中还没有更多的IO入队,底层就把队列中所有IO都处理完了。欠载的后果就是底层无法获取足够多的IO请求,那么吞吐量就会降下来。这就像抽水机一样,大家可能有人见过工地上的抽水机,咣叽咣叽的,活塞每运动一次,水流就冒出来,而当活塞退回原位从水源吸水的时候,出水端水流就小了。活塞每次能吸水的容量,就是队列深度。
好在,在IO路径处理上,系统并不是处理完队列中所有IO之后,才允许新的IO入队,IO可以随时入队(上游模块压入队列等待处理)或者出队(下游模块从队列中取走执行),但是,这种方式也带来了一个问题,就是锁的问题。出队入队操作,都要锁住整个队列首尾指针对应的变量,因为不能允许多个模块同时操作指针变量,会不一致。这一锁定,性能就会受到影响,从而导致频繁欠载。有些号称无锁队列,只不过是将锁定操作从软件执行变成利用硬件原子操作指令来让硬件完成,底层还是需要锁定的。那么,这方面如何优化?道理很简单,大家都挤在一个队列里操作,何不多来几个队列呢?队列之间一般没有关联,根本不需要队列间锁定,这就增加了并发度,能够释放固态介质的性能。在最新的Linux内核中,通用块层已经实现了多队列。所以,如果还想利用现成的块层来节约开发量,那么无疑要选择新内核版本了。
3. 抛弃原有的协议栈,包括块层,自己开发新协议栈
通用块层之所以通用,就是因为它考虑了最通用的场景,定义了很多像模像样的数据结构、接口、流程,而且加入了很多功能模块,比如LVM,软Raid,Device Mapper,DRBD、IO Scheduler等等,虽然这些模块多数都可以被bypass掉,但是这些东西对于那些想完全榨干性能的架构师来讲,就多余了。
有些AFA或者一些分布式存储系统在IO路径中完全抛弃块层,而自己写了一个内核模块挂接到VFS层下面,接受应用发送的IO请求,经过简单处理之后直接交给底层协议栈(比如SCSI协议栈)处理。不幸的是,SCSI协议栈本身则是个比块层还要厚的层。IO出了龙潭又入虎穴,对于基于SATA/SAS SSD的AFA来讲,SCSI层很难绕过,因为这个协议栈太过底层,SCSI指令集异常复杂,协议状态机、设备发现、错误恢复机制等哪一样都够受的,如果抛弃SCSI协议栈自己开发一个新的轻量级SCSI协议栈,那是不切实际的,你会发现倒头来不得不把那些重的代码加回来,因为SCSI体系本身的复杂性已经决定了协议栈实现上的复杂性。
所以,基于SATA/SAS SSD搭建的固态阵列,其性能也就那么回事,时延一定高。然而,如果使用的是PCIE闪存卡或者2.5寸盘的话,那么就可以完全抛弃SCSI协议栈。有些PCIE闪存卡的驱动中包含了自定义的私有协议栈,其中包含了指令集、错误处理、监控等通用协议栈的大部分功能,其直接注册到块层;而NVMe协议栈迅速成了定海神针,参差不齐混乱不堪的协议栈,不利于行业的规模性发展,NVMe协议栈就是专门针对非易失性高速存储介质开发的轻量级协议栈,轻量级的指令集和错误恢复逻辑,超高的并发队列数量和队列深度。AFA后端如果使用NVMe闪存卡/盘的话,那么这块也就没有什么可优化的了。如果还想优化,那就得从更底层来优化了,也就是连NVMe协议栈也抛掉,只保留PCIE闪存卡/盘的LLDD驱动,上面的部分全部重写,不过这样看上去没什么必要,因为LLDD上层接口也是符合NVMe规范的,设备固件也只能处理NVMe指令,所以,针对已经优化过的协议栈继续优化,受益很低,成本很高。要想继续优化,还有一条路可走,那就是连内核态驱动都抛掉。
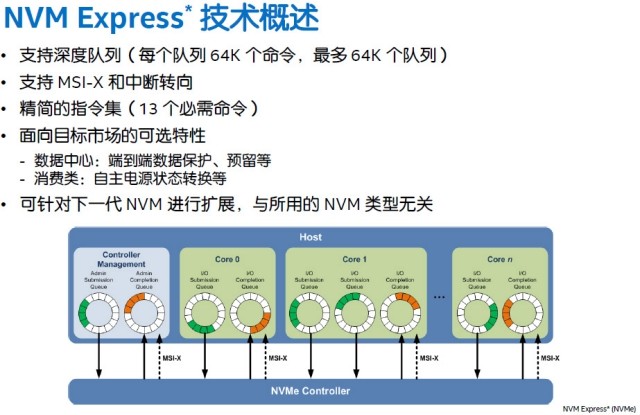
4.抛弃原有的协议栈和设备驱动,完全从头开发
块层可以抛,底层协议栈也可以抛,最底层的内核设备驱动是否也可以抛弃呢?若为性能故,三者皆可抛!操作系统内核的存在,对性能是无益的,内核增加了方便性和安全性,必然牺牲性能。如果要追求极致性能,就要连操作系统内核都Bypass掉。当然,运行在OS中的程序是不可能脱离OS内核而存在的,但是这并不妨碍其打开一个小窗口,将IO指令直接发送给硬件,无需经过内核模块的转发,这就是所谓内核Bypass,指的是IO路径上的大部分操作不陷入内核。
当然,这需要PCIE闪存卡/盘厂商首先实现一个很小的代理驱动,这个驱动负责将PCIE设备的寄存器空间映射到用户程序空间,之后还要负责响应中断和代理DMA操作,其他时候就不参与任何IO处理了,用户程序可以直接读写设备寄存器,这样可以实现更高的性能,但是对开发者能力要求甚高,其需要自行实现一个用户态的IO处理状态机,或者说IO协议栈,搞不好的话,连原生驱动的性能都不如。所以,这已经超出了目前多数产品开发设计者的可承受范围,在如今这个互联网+的浮躁时代,多数人更注重快速出产品,而不是十年磨一剑铸就经典。
5.针对多核心进行优化
不管利用上述哪种设计模式,都需要针对多核心CPU平台进行优化。有些存储厂商在几乎十年前就开始了多CPU多核心的系统优化,而某大牌厂商,据冬瓜哥所知,直到几年前才着手优化多核心多CPU,当时,其产品虽然硬件配置上是多核心多CPU,其实其软件内部的主要IO模块根本都是串行架构的,也就是根本用不起来多CPU,具体厂商冬瓜哥就不提了,只是想让大家明白一个事情,就是厂商的这些产品,表面吹的很光鲜,而后面的水可能很深,有时候可能也是很黑的。
6.采用专用FPGA加速
存储系统到底是否可以使用硬加速?这得首先看一下存储系统的本质,存储系统的最原始形态,其实不是存储,而是网络,也就是只负责转发IO请求即可,不做任何处理(或者说虚拟化),如果仅仅是IO转发,那不就成了交换机了么,是的,交换机是否可以使用通用CPU来完成?可以,软交换机就是,但是性能的确是不如硬交换机的,硬交换机直接用Crossbar或者MUX来直接传递数据,而CPU则需要通过至少一次内存拷贝,收包、分析+查路由、发包,这个处理过程时延远高于硬交换,虽然可以用流水线化处理以及并行队列的障眼法也达到较高的吞吐量,但是只要考察其时延,立马露馅。
再来说说增加了很多功能的存储系统,也就是虚拟化存储系统,其内部使用通用CPU完成所有逻辑,不仅是简单的IO转发了,而且要处理,比如计算XOR,计算Hash,查表计算Thin卷的地址映射,Raid2.0元数据的更新维护,响应中断,拷贝数据,等等。那么上述这些工作,哪些可以硬加速呢?那些大运算量,大数据拷贝量,模式重复固定的运算,都可以被硬加速,比如XOR计算,重删Hash计算,固定模式的元数据维护(比如bitmap、链表、bloomfilter等)、字符串匹配搜索、指令译码等。(详情可参考冬瓜哥的“大话存储”公众号的第一篇文章《聊聊FPGA/CAPI/CPU》)。
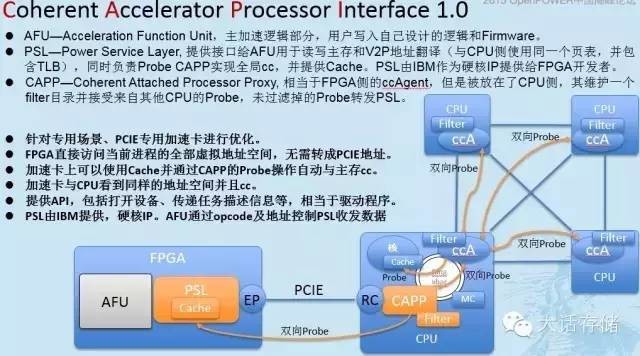
至于复杂的判断逻辑或者说控制逻辑,尤其是全局控制部分,还得通用CPU出马,因为在这个层面上,充满了变数。所以,即便是采用了FPGA的存储系统,其一定也是靠通用CPU来完成总体控制的,有些单片FPGA存储系统,那也不过是利用了FPGA内部集成的通用CPU硬核来做总控罢了。目前市面上的FPGA,已经不单纯是一大块可编程逻辑了,与其说是FPGA,不如说是带可编程逻辑的SoC更合适,或者说是把一堆成熟外围器件比如DDR控制器、PCIE控制器、通用CPU、RAM、SRAM等,与FPGA可编程部分集成到一起的一个整体单片系统,该系统也是什么都能做,虽然内部集成的核心可能远比不上x86平台的性能,但是对于专用系统,基本已足够。所以,用了FPGA就不需要Linux了么?非也。用了FPGA就不需要NVMe驱动了么?非也。FPGA在这里充其量起到一个offload一些计算的作用了。
【方式2】共存但不交叉
Nima,方式1这一节篇幅竟然这么长,冬瓜哥自己都怕了。再来说说方式2,共存但不交叉。这个方式是指在同一个存储系统内,既有固态介质又有机械盘,但是它们不被放置在同一个Raid组内,比如8个机械盘做一个Raid5,另外4个SSD又做了一个Raid10,各玩各的互不干扰。说不干扰,是假的,这里的干扰,是一种更深层次的干扰,典型的代表是“快慢盘问题”,能力强的能力弱的,在同一个体系内,会发生什么问题?大家都清楚,能力弱的会拖慢能力强的。
对于存储系统,一样的,系统内的资源是有限的,比如某个链表,其中记录有针对机械盘的IO的指令和数据,这些IO的执行相对于固态介质来讲简直是慢如蜗牛,那么,当固态盘执行完一个IO之后,由于这些被机械盘占用的资源无法释放,新的IO就无法占用这些资源,导致固态盘在单位时间内的闲置率增加,那么性能就无法发挥,被慢盘拖慢了。同样的现象甚至出现在全机械盘系统内,如果某个盘有问题,响应时间变长,除了影响Raid组内其他盘之外,也影响了其他Raid组的性能发挥。解决这类问题,就要针对固态盘开辟专用的资源,而这又会增加不少的开发量和测试量。
【方式3】散热设计和供电
还有一种方式,是将固态介质用作元数据的存储,比如存放Hash指纹库、Thin/分层/Raid2.0的重映射表等、文件系统元数据等量较大的元数据,这些元数据如果都被载入内存的话恐怕放不开,因为存储系统的内存主要是被用来缓存读写数据,从而提升性能,如果将大量空间用于元数据存放,那么性能就无法保证,但是反过来,如果大部分元数据无法被载入内存,那么性能也无法保证,因为对于文件系统、分层、Raid2.0等,每笔IO都无法避免查表,而且是个同步操作,如果元数据缓存不命中,到磁盘载入,这样性能就会惨不忍睹。所以固态盘此时派上了用场,可以作为针对元数据的二级缓存使用,容量足够大,读取时响应速度够快,更新则可以在RAM中积累然后批量更新到Flash,所以即便Flash写性能差,也不是问题。

【方式4】非易失性写缓存/NVRAM
大家都知道分布式系统一般是利用节点间镜像来防止一个节点宕机之后缓存数据的丢失。而如果是所有节点全部掉电呢?比如某长时间停电,或者雷击等导致包括UPS在内的全部电力供应中断,整体掉电的几率还是存在的。此时,缓存镜像依然无法防止丢数据。而传统存储内部有一个BBU或者UPS,相当于二级保险。
对于分布式系统,要增加这种二级保险的话,成本会非常高,因为分布式系统的节点太多,但是的确有些分布式系统厂商采用了NVRAM/NVDIMM来保护关键元数据或者Journal,而没有用BBU来保护整个机器的内存,因为后者需要定制化硬件设计,服务器机箱内无法容下BBU了。
目前,NVDIMM需要改很多周边的软硬件,不透明,而基于PCIE接口的NVRAM卡则可以无需修改BIOS和OS内核即可使用,其可以模拟成块设备,或者将卡上的RAM空间映射到用户态。随着NVDIMM,以及Intel Apache Pass项目的推进,相信后期非易失性DIMM会逐渐普及开来。
【方式5】透明分层
上述介绍的混合机械盘和固态盘的方案,对应用来讲都不是透明的,都需要应用或者系统管理员自行感知和安排数据的保存位置。透明分层则是一种对应用透明的加速方案,传统存储产品最看重对应用透明,所以自动分层技术成为了传统存储的标配特性。大家的做法类似,都是自动统计每个数据块的访问频率,然后做排序,将热点数据从低速介质上移到高速介质,冷数据则下移到低速介质。没太大技术含量,无非就是谁家能做更小的分块粒度,热点识别的精准度就越高,但是耗费的元数据空间越大,搜索效率越低,所有参数都是各种平衡的结果。
自动分层有一个尴尬的地方,就是对于新写入的数据块的处理策略,是先写入低速分层再向上迁移,还是与先写入高速分层再“下沉”给应用的体验有区别,哪个能始终保证写入性能?这些策略,每个厂商都有各自的选择。在此冬瓜哥想用一个典型设计来想大家介绍一下自动分层方案在实际产品中的全貌。
目前针对自动分层方案,业界的产品中,Dell在其Fluid Data系列方案中有两个技术比较有特色。第一个是Fast Track技术,也就是系统可以将热数据透明的放置在磁盘的外圈,而冷数据则搬移到内圈。外圈转速高,等待时间短,可以获得更高的IOPS和带宽。
第二个则是利用写重定向快照来实现读写分离的、基于全固态存储系统的跨Raid级别(Raid10和Raid5)的分层方案,号称可以以磁盘的价格实现全固态存储的性能,这个方案冬瓜哥认为还是非常有特色的。
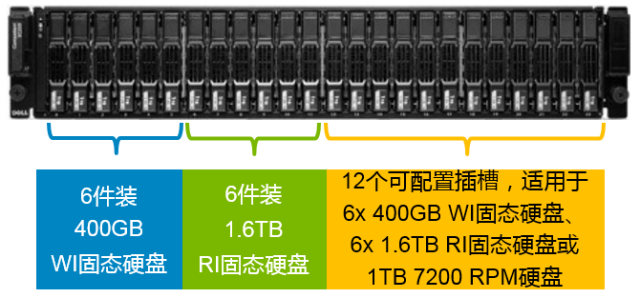
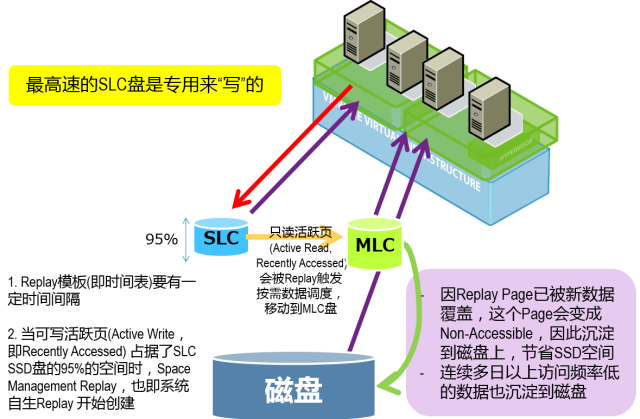
首先,系统将Tier1层,也就是固态介质层,分为两个子层,一个是采用Raid10方式的且由SLC Flash构成的子层,这个层采用无写惩罚的Raid10冗余保护方式,而且采用寿命和性能最高的SLC规格的Flash介质,所以仅承载写IO和针对新写入数据的读IO,基本不必关心寿命和性能问题,所以又被称为Write Intensive(WI)层,当然,这一层的容量也不会很大;另一个是采用Raid5方式的且由MLC Flash构成的子层,仅承载读IO,所以Raid5的写惩罚并不会导致读性能下降,又被称为Read Intensive(RI)层,这一层相对容量较大。如下图所示为一种典型的固态+机械盘混合存储配比方案。
那么,Dell流动数据方案是如何实现读写分离的呢?其巧妙的利用了写重定向快照技术(注:Dell Compellent系统里的快照被称为“Replay”)。如下图所示,类型一中的方式,属于传统分层方式,也就是白天统计访问频率,傍晚或者深夜进行排序和热点判断以及数据搬移,这种方式是目前多数厂商普遍的实现方式,没有什么亮点。然而,Dell流动数据方案除了支持这种传统方式之外还支持另一种即图中所示的“按需数据调度”分层方式。
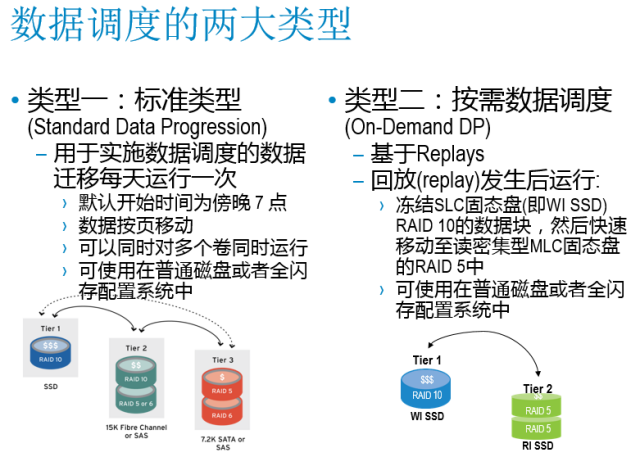
这种比较奇特的方式可以实现读写分离,但是必须依赖于快照,也就是说,只有当快照生成之后,这种方式才起作用,如果用户没有主动做快照,那么系统也会后台自动做快照来支撑这种分层方式的执行,冬瓜哥在此想为大家介绍一下这种方式的具体机理。
大家都知道写重定向快照的底层原理(不了解的可以阅读冬瓜哥的《大话存储(终极版)》),快照生成之后,源数据块只会被读取,不会被原地覆盖写入,因为覆盖写入的数据块都会被重定向到新的空闲数据块,在Dell流动数据按需数据调度技术中,这些新覆盖写入的数据块依然会被写入到Raid10模式的Tier1 SSD中,也就是WI层,那么,尚存在于WI层的源数据块后续只会被读取(这类数据块又被称为“只读活跃页”),不会被原地覆盖写入,那么就没有必要继续在WI层中存放,可以将它们在后台全部转移到Raid5模式的Tier1 SSD中也就是RI层存放,对于那些已经被更改过一次的数据块(新写入数据块被重定向,对应的原有数据块此时就被称为“不再访问的历史页”),其永远不会被生产卷所访问到,那么就可以将这些数据块直接迁移到最低性能层级,也就是Tier3的机械盘中存储。
如果系统内当前并没有生成快照,或者所有快照已经被用户删除,那么当SLC的WI层级达到95%满之后,系统会自动触发一个快照,目的是重新翻盘,将快照之后新写入的块写到SLC,而之前的块搬移到MLC层级中,已被覆写的块直接搬移到机械盘,后续如果再达到95%满,就再做一次快照重新翻盘,利用这种方式,可保证SLC层级只接受写入操作以及针对新写入块的读操作,而MLC层级只接受读操作,实现了读写分离,充分发挥了SLC和MLC各自的优势。戴尔建议每天至少生成一个Replay,可以安排在负载不高的时段,并根据数据写入量来提前规划SLC分层的容量。95%这个触发机制只是最后一道防线。
另外,当某个数据块被搬移到RI层后,如果发生了针对该块的写入操作,那么,其被写入之后(新块写到SLC层),该块在MLC中的副本就不会再被生产卷访问,系统会将其迁移到最低层级的机械盘从而空出MLC层的空间。另外,MLC中那些长期未被读到的数据块,也会被系统迁移到磁盘层。
利用这种写重定向快照技术和多个层级的介质,Dell Fluid Data解决方案实现了读写分离,让写总是写到SLC,读总是读MLC,同时MLC中的数据再慢慢向下淘汰到机械盘,这种方式相比定期触发数据搬移的传统分层技术来讲,更加具有实时性,在SLC层和MLC层之间的流动性非常强,能够应对突发的热点,更像是一种实时缓存;而在MLC和机械盘之间,流动性较低,除了将快照中被新数据“覆盖”的块拷贝到机械盘之外,还定期根据长期的冷热度将MLC层中的块搬移到机械盘,这又是传统分层的思想。所以Dell Fluid Data分层解决方案是一个结合了缓存和分层各自优点的,利用写重定向快照技术充分发挥了SLC和MLC各自读写特长的优秀解决方案。
【方式6】透明缓存
然而,自动分层有个劣势,就是其识别的“热点”必须是长期热点,对于突发性短期热点,无能为力,因为其统计周期一般是小时级别的,有些热点恐怕几分钟就过去了。另外一个劣势,就是无法判断出人为热点,比如5分钟之后,管理员明确知道某个文件或者某个库一定会招致很高的访问压力,此时,传统的自动分层就无能为力,因此冬瓜哥在之前的“可视化存储智能解决方案”对应的产品中,就加入了这种对人为热点的支持,提供自动和手动以及混合模式,可以让用户灵活的决定将什么数据放在哪里,但是依然是对应用透明的,只相当于给存储系统提供了准确的提示信息而已。
此外,针对这种突发性实时热点,一个最典型的粒子就是VDI启动风暴场景,这个突发热点是分层没法解决的,除非使用了链接克隆然后利用冬瓜哥在“可视化存储智能解决方案”中所设计的类似技术,将克隆主体数据手动透明迁移到固态介质上。
应对这种突发热点,一种更合适的方式,就是固态介质缓存。缓存比分层更加实时,因为所有的读写数据先从内存进入SSD缓存,再到机械盘,所有数据都有进入缓存的机会,利用LRU及其各种变种算法,能将那些短时间内访问频繁的数据留在SSD中。所以,应对VDI启动风暴这种场景,使用缓存方式既能保证透明又可以获得不错的性能。
针对缓存解决方案,Dell的Fluid Cache for SAN 解决方案将固态介质缓存直接放置在了主机端,利用更靠近CPU的PCIE闪存卡作为缓存介质,并且多台服务器上的固态介质还可以形成一个全局统一的缓存池。整体的拓扑构成如下图所示:
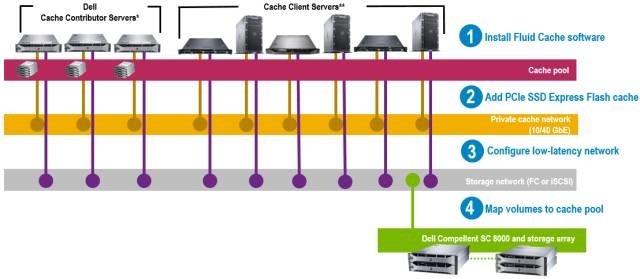
一个缓存域最多由9台服务器组成,其中至少要包含3台缓存节点(插有PCIE闪存卡),其余6台节点可以是客户端节点(也可以是缓存节点),客户端节点通过专用的Client向缓存节点直接读取缓存数据,当然,缓存节点自身的应用程序也可以直接读取本地或者其他缓存节点的数据。读写缓存走的是万兆或者40GE网络,来保证低时延,同时这个网络也承载缓存镜像流量,每个节点的写缓存,会通过RDMA镜像到其他缓存节点一份,当写缓存被同步到后端的Compellent存储系统之后,才会作废对端的镜像副本,以此来保障一个节点宕机之后的系统可用性。某个卷的数据块可以被配置为仅缓存在本机的PCIE闪存介质中,也可以均衡缓存到所有节点(默认配置)。
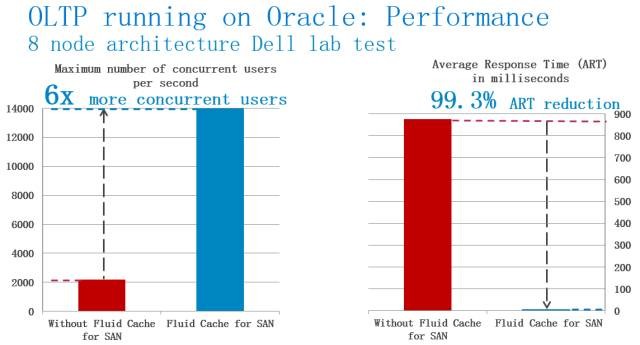
缓存模式的这种强实时性,使得其非常适合于实时加速,比如OLTP场景,下图所示为由一个8节点缓存集群的性能加速效果,使得可并发的用户数量达到了6倍,同时平均响应时间降低了99.3%。

我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
相关推荐
-
Dell EMC合并一周年回顾
在并购交易结束12个多月后,我们的专家对Dell收购EMC ,有史来最大的存储技术合并进行了评估。
-
存储极客 | 这些硬盘参数你都懂得吗?(下篇)
硬盘读写数据也是有一个“疲劳磨损”的过程,希望能够引起人们对可靠性的关注。尽管这是我熟悉并关注近20年的领域,为撰写本文还是查阅、整理了大量资料。
-
存储极客 | 这些硬盘参数你都懂得吗?
目前硬盘行业总体营收受SSD冲击开始出现一定下滑,但若干年内仍将保持可观的需求,特别是大容量型号的性价比优势。而且这一市场已经由于成熟而细分
-
纹秤对弈VDI:超融合赢了传统存储
在并购了业内领先的瘦客户端、零客户端及云计算解决方案供应商Wyse之后,加上与VMware和微软的紧密合作,戴尔能够提供完整而丰富的端到端VDI方案,这一点是许多超融合/ServerSAN厂商所不具备的。