
引言
大数据已成为HPC最重要的应用领域,戴尔PowerEdge FX2集刀片和多节点机架式服务器的技术优势于一身,不仅为用户化解计算密度、空间占用、网络布线的权衡之困,更令用户轻松获得顶级计算密度、存储性能,以及超快网络应用。
在之前的《从HPC到大数据:戴尔-Intel Lustre存储解决方案》一文中,我们曾经谈到用于高性能计算的文件系统已经开始添加大数据(Hadoop)方面的支持。
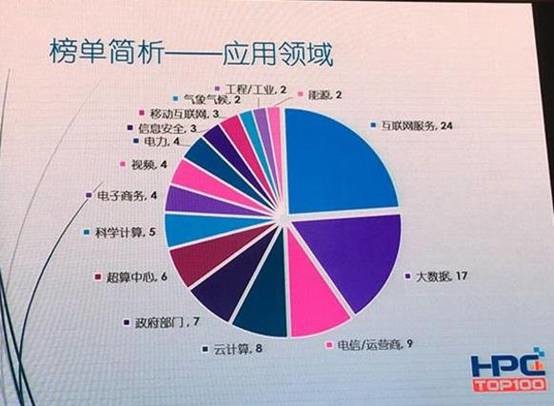
如上图,从中国超算Top100来看大数据已经成为HPC最重要的应用领域。
那么,大数据分析对高性能计算设备——服务器、存储和网络方面有什么新的要求吗?在本文中我们仍聚焦基础架构,为大家介绍上述领域的创新,包括几款已经或者即将发布的特色产品,以及真实的客户案例。
HPC服务器进化方向
计算密度、GPU/协处理器
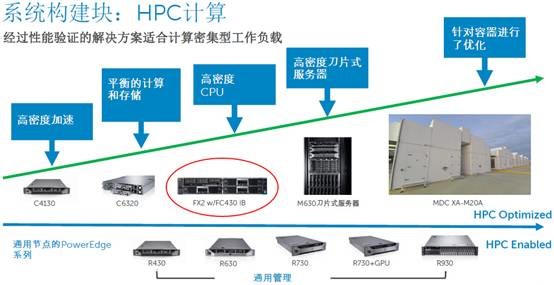
这张图是戴尔服务器产品线在HPC计算单元中的布局,蓝色箭头最底下一行是通用节点,即标准化的1U/2U/4U服务器。上面则是HPC优化型产品,最左边的PowerEdge C4130是1U高度,支持4块NVIDIA Tesla GPU或者Intel Xeon Phi co-processors计算加速卡;C6320则是比较典型的2U 4节点;安装FC430节点高密度CPU的FX2是本文要讨论的重点;再往右有M630刀片服务器;最右边是定制的模块化数据中心。
HPC应用多为大规模集群部署,计算密度直接关系着空间占用,进而影响到机房设计、网络布线等方面。早期的计算能力基本上是堆CPU;后来随着GPU/协处理器在通用计算领域的应用,算是第二个设计方向。当然后者还要特别考虑编程和效率的问题。
本文讨论重点之一就是提高HPC的CPU计算密度。
服务器形态进化
来自Dell的极限密度
回首当年,服务器从机架式衍生出刀片式,不仅提高了计算密度,集成了网络交换单元,还可以集成共享存储单元(DAS或者iSCSI刀片存储模块)。刀片最大的优势是管理,能降低运维工作量。
曾经有一段时间,连超大型HPC集群都开始选择刀片式服务器。不过一方面它在同等计算能力下的成本要高于机架式服务器,另一方面它的计算密度还有没有可能再提高?
于是在数年前,开始出现一些多节点机架式服务器,比如1U双节点、2U四节点——被人们称为双子星和四子星。在保持刀片计算密度的同时,成本上显著降低,加上机架空间的节省,TCO比传统机架式服务器还要低,因此受到一些云计算和HPC用户的青睐,比如戴尔PowerEdge C系列中的C6320。
多节点机架式服务器中目前最流行的就是2U四节点,门槛不高(自己做不了的品牌可以找ODM供应商)。与刀片相比,它们没有集成网络交换和强大的管理功能;与机架式相比,它们的存储和I/O扩展性一般;为了优先考虑成本,品质上就可能有所取舍。
当我们看到戴尔PowerEdge FX2时,第一印象是它集合了刀片和多节点机架式服务器的技术优势。首先是计算密度——2U内最多可以支持8个双插槽Xeon CPU节点;其次是灵活性——可选多种服务器节点;还有扩展性——包括可拆分的DAS存储节点、多种网络直通/交换模块;以及CMC机箱集中式管理。

以上是PowerEdge FX2模块化系统支持的组件,这里除了服务器节点、还包括存储单元和网络交换模块(I/O聚合器)。图中的数量比较多,是因为每种型号还有不同的硬盘/SSD驱动器托架可选。
正是这种灵活性,使FX2可以有多种应用方向,比如我们在《硬件辅助超融合:任意云中的全闪存VSAN》一文中介绍的分布式存储/超融合。而本文既然是谈HPC,自然是讨论计算密度最高的FC430。

PowerEdge FC430的一大特点就是超高的计算密度——2U 8个1/4宽度双插槽节点,尽管由于功耗和散热的限制,它只支持到14核Xeon E5-2600v3 CPU,但2U内密度已高达224 core,因为空间关系,内存的密度有所权衡——64 DIMM(每节点8条,每通道1条)。
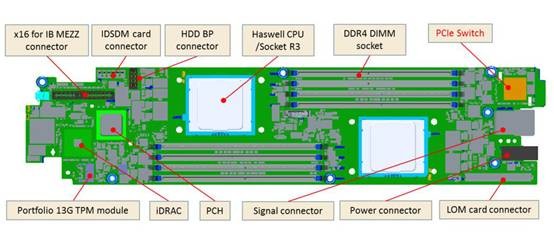
FC430专为HPC设计的
InfiniBand接口
超高的计算密度,很容易让人联想到HPC高性能计算应用。为此,FC430除了每节点2个1.8英寸SSD的存储配置之外,还有一种单SSD配置——就是为了在前面板上增加一个InfiniBand高速网络接口(下面有一张放大图)。

值得一提的是,PowerEdge FC430还支持一种单插槽Xeon E5-1600 v3的配置,这就是针对HPC应用中对主频敏感的那些(单线程优化)程序,可以选择降低CPU核心数来提高主频。
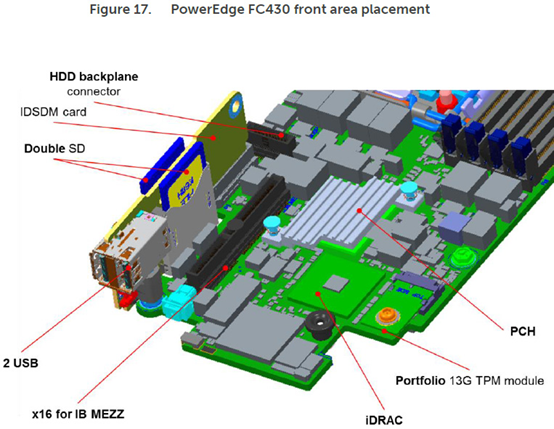
如上图,我们可以看到FC430主板PCB上的元件密度,以及前端IB Mezz夹层扩展卡插槽的位置。这对于服务器硬件设计能力也是一种考验。
据我们了解,国内某高性能计算用户选择戴尔PowerEdge FX2平台部署了超过200计算节点的FC430,由于机房设计合理,没有遇到散热和供电方面的问题。存储方面采用Lustre集群,包括8个OSS(对象存储服务器)节点。整体互连选择了10Gb以太网,配置Dell Networking Z9500万兆交换机。
集中管理
CMC堆叠简化网络
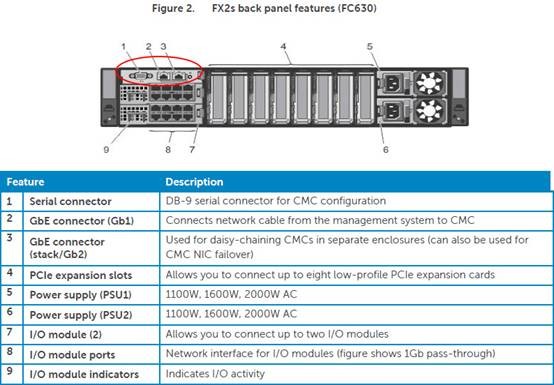
如上图,我们用红圈标出的部分是PowerEdge FX2机箱的CMC管理模块,上面的Gb2网口可以用于堆叠模式。比如在一次测试中,10个机箱的CMC以菊花链形式连接在一起,相邻的两台之间仅需要超短线缆,而对外只用一条上联网线,可以显著降低管理网络的复杂度。
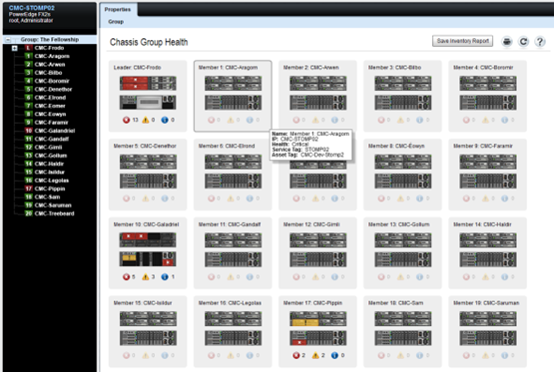
通过Chassis Group,多套PowerEdge FX2可以在单个界面中统一管理。
性能怪兽DSSD
在HPC存储中的应用案例
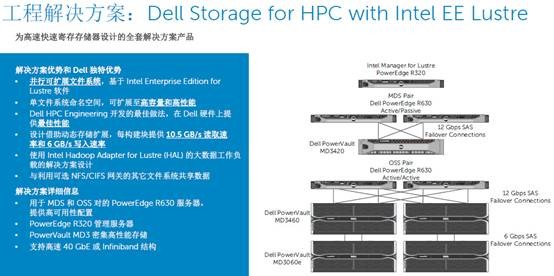
许多朋友应该知道,Lustre和GPFS是HPC存储使用最多的文件系统,它们的共同特点是支持大规模集群并行提供高容量和高带宽。那么随着大数据分析在高性能计算中的增多,有没有需要高IOPS、低延时存储的场景呢?
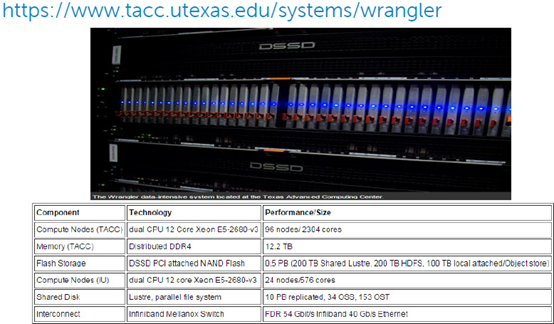
位于美国德州Austin TACC(田纳西高性能计算中心)的wrangler HPC系统,戴尔作为硬件供应商参与了该项目,提供服务器设备等。该项目最大的亮点是采用了EMC即将正式发布的闪存存储DSSD。

DSSD本身闪亮的性能指标我们就不再这里展开了,大家有兴趣可以关注近日发布的消息。上图引用自赵军平老师的文章,在TACC这套HPC系统中,预期单计算节点的访问性能即可达到最高12GB/s和超过200万IOPS。
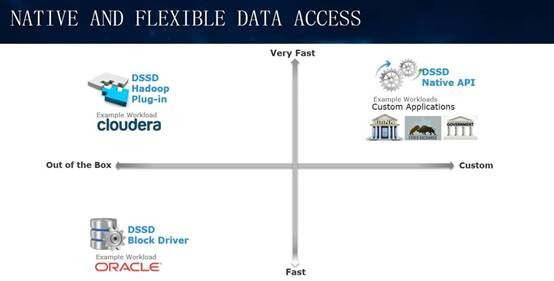
DSSD的另一大特色就是Key-Value对象访问接口,包括原生REST API以及Hadoop插件;另外它也提供Block(块)和POSIX兼容的文件访问,其好处就是兼容Oracle数据库等传统应用。

DSSD专门针对高性能数据密集型工作负载设计,上图中列出了它的部分应用领域:(商业)欺诈检测、风险分析、预测模型、基于流式数据的准实时分析、金融-交易模型、政府机构-设计仿真、石油&天然气-(地震数据)求解仿真网格、生命科学&研究。
在这里面有许多属于高性能计算领域,我们预计随着戴尔与EMC的合并,新公司强有力的产品组合将提供更有竞争力的HPC解决方案。
新一代网络互连
100Gb的OPA要来了

伴随单节点计算和存储性能的不断提高,网络I/O瓶颈也需要突破。我们看到在存储方面DSSD创新地采用了PCIe主机接口;而计算节点之间除了Mellanox 100Gb/s EDR InfiniBand之外,还有同样带宽、备受关注的下一代互连技术——为可扩展HPC系统设计的Intel Omni-Path架构(简称OPA)。
如上图,戴尔与Intel合作,准备了H系列OPA交换机和网卡。与同样速率达到100Gb/s的以太网卡和IB HCA相似,OPA网卡也采用PCIe x16接口以满足其带宽。OPA的颠覆之处是将会集成到未来的Intel CPU当中,届时预计会迎来该技术在HPC乃至更多领域的爆发。
顶级计算密度、存储“性能怪兽”、最快的网络都准备好了,戴尔HPC还差什么呢?

我们一直都在努力坚持原创.......请不要一声不吭,就悄悄拿走。
我原创,你原创,我们的内容世界才会更加精彩!
【所有原创内容版权均属TechTarget,欢迎大家转发分享。但未经授权,严禁任何媒体(平面媒体、网络媒体、自媒体等)以及微信公众号复制、转载、摘编或以其他方式进行使用。】
微信公众号

TechTarget
官方微博

TechTarget中国
相关推荐
-
Red Hat新推Storage one捆绑硬件及SDS
Red Hat为其开源存储软件新增设备选项,本周该公司推出Storage One,这是与服务器硬件供应商共同设 […]
-
数据和云计算对CIO工作的影响
近日笔者在报道云计算对首席信息官(CIO)的影响时,总是会得出相同的观点:CIO的工作已经不再是曾经的技术工作 […]
-
冬瓜哥新作《大话存储后传》读后随感
今天要向大家隆重推荐一部有关存储的新作——冬瓜哥的《大话存储后传》,副标题是“次时代数据存储思维与技术”。
-
树立标杆 华为存储凸显引领气质
IT的发展日新月异,不断激增的数据量和快速变化的业务模式给传统的基础架构、数据存储带来了新的挑战,市场在呼唤系统更稳定、性能更高、更加融合的存储,这也就不奇怪各大厂商的高端存储纷纷出炉。